
Atención es todo lo que necesitas: el paper que lo cambió todo

En posts anteriores ya hablamos de los embeddings —qué son, cómo se usan para representar palabras, frases y documentos—. Pero hoy vamos un paso más allá y nos adentramos en un clásico absoluto en el mundo de la inteligencia artificial generativa: el paper Attention Is All You Need. Este artículo dio lugar a la arquitectura conocida como Transformer, que sustenta buena parte de los modelos que están detrás del boom de la IA (incluidos los grandes modelos de lenguaje). (Wikipedia)
Queremos explicarlo de forma divulgativa, accesible para todo el mundo, sin perder la parte técnica. De modo que si tienes conocimientos de embeddings, vocabulario de IA, quizá te irás familiarizando con cómo funciona “por dentro” esa gran caja negra llamada Transformer.
¿Por qué este paper es tan relevante?
- El artículo fue publicado en 2017 por Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Łukasz Kaiser e Illia Polosukhin. (arXiv)
- Propuso una arquitectura que prescinde de redes recurrentes (RNNs) y convolucionales (CNNs) para tareas de secuencia a secuencia (seq2seq), y en su lugar usa solo mecanismos de atención. (papers.neurips.cc)
- Por ese motivo se considera un antes y un después: permitió modelos más escalables, paralelizables, y generó la base para modelos como BERT, GPT‑3/GPT‑4, etc. (Wikipedia)
¿Qué es la “atención” (attention) y por qué importa?
Para entender bien el paper, conviene que recordemos qué es un embedding (ya lo vimos) y cómo funcionaban antes los modelos de lenguaje secuenciales:
- Antes de los Transformers se usaban RNNs (o LSTMs/GRUs) para procesar texto como secuencias: palabra tras palabra, manteniendo un “estado” interno que iba acumulando información.
- Estos modelos tienen dos limitaciones importantes:
- Dependencia de pasos anteriores: la información que apareció al principio puede perderse o “diluirse” al final de la secuencia.
- Difícil de paralelizar: al tener que procesar palabra por palabra, no se pueden aprovechar al máximo los cálculos simultáneos en hardware moderno.
- Entonces aparece la idea de atención: en vez de depender únicamente del estado anterior, un modelo puede “mirar” directamente todas las posiciones del input y decidir “qué partes me interesan más” para producir la salida.
En el paper se define la atención escalada de producto punto (scaled-dot-product attention) como:
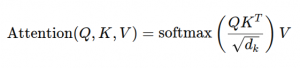
donde (Q) (query), (K) (key) y (V) (value) son matrices vectoriales. (Wikipedia)
Explicándolo de forma simple: para cada “consulta” (query) se calcula cuánto “pesan” todas las “claves” (keys) y se usa eso para combinar los “valores” (values). En lenguaje natural: “esta palabra (o token) ¿a qué otras palabras le debe prestar atención para tomar su decisión?”.
Arquitectura del Transformer: explicado de forma amigable
Aquí entramos en la parte técnica, pero lo explicaremos por analogía para que sea comprensible:
Encoder y decoder
El modelo propuesto tiene dos bloques principales: un encoder que procesa la secuencia de entrada, y un decoder que genera la secuencia de salida (por ejemplo, traducción de un idioma a otro). (Medium)
Cada uno está compuesto por varias “capas” idénticas (en el paper original se usaron 6 capas de encoder y 6 de decoder). (Medium)
Self-attention (auto-atención)
En el bloque encoder, cada token “mira” todos los tokens de la secuencia (incluido él mismo) y decide cuánto debe “atender” a cada uno. Esto permite capturar dependencias largas (por ejemplo la primera palabra con la última) sin procesar palabra por palabra.
Analogia: imagina que al leer una frase, para entender una palabra no solo miro la anterior, sino también que la primera palabra me dé contexto.
Multi-head attention
Pero no basta con mirar una “perspectiva única”. El modelo tiene varias “cabezas” de atención (heads), cada una aprende a mirar diferentes relaciones (una puede ver relaciones gramaticales, otra semánticas, otra de contexto amplio). Luego se combinan todas esas cabezas. (Wikipedia)
Analogía simple: como si varios lectores miraran la frase desde diferentes ángulos al mismo tiempo, luego se reunieran para decidir la interpretación común.
Positional encoding (codificación de posición)
Como eliminamos el procesamiento secuencial (RNN), el modelo necesita saber en qué orden aparecen los tokens. Para eso se añade al embedding original una “codificación de posición” usando funciones de seno y coseno. (Wikipedia)
Analogía: al leer una frase, no solo sé qué palabra es, sino “esta está en la posición 5, esta en la 1”… y esa información también importa.
Flujo simplificado
- Tokenizamos la frase → convertimos en IDs → vemos sus embeddings.
- Al embedding le sumamos la codificación de posición.
- Pasamos por varias capas del encoder: cada capa hace self-attention + feed-forward + normalización + residuales.
- El decoder toma la salida del encoder + su propio mecanismo de atención (mira al encoder, y a lo que ya ha generado) → genera token a token la secuencia de salida.
- Finalmente, se obtiene la probabilidad de cada token de salida, se selecciona el más probable, se repite hasta fin.
¿Cuál fue la gran aportación frente a lo que había antes?
- El modelo es más paralelo: no necesita procesar paso a paso como un RNN. Eso permite entrenar más rápido, usar hardware moderno mejor. (Wikipedia)
- Mejora la capacidad para capturar dependencias largas: una palabra puede atender directamente a otra que esté muy lejos en la secuencia.
- Simplifica la arquitectura: al eliminar complicaciones de recurrencia/convolución y centrarse en atención + feed-forward.
- Fue la base para los grandes modelos generativos que hoy conocemos.
Para qué fue probado y qué resultados consiguió
En el paper original probaron traducción automática (inglés→alemán, inglés→francés) y obtuvieron resultados mejores que los modelos anteriores, con menor coste de entrenamiento. (arXiv)
Por ejemplo, en WMT-14 inglés→francés obtuvieron un BLEU de 41,8. (arXiv)
Esto demostró que la arquitectura no era solo teórica, sino práctica y competitiva.
Una explicación con analogías para “todo el mundo”
Imagina que estás en una sala de reuniones (tu secuencia de palabras). Antes, con RNN, la reunión era tipo “yo hablo, luego otro, luego otro…” en fila: cada uno tiene que esperar su turno, y lo que dijo el primero puede que ya esté olvidado cuando llega el final.
Con el Transformer es como si todos los participantes vieran al mismo tiempo a todos los demás — un “círculo de atención” — y cada uno decide escuchar a cualquiera de los demás, y además “mirar” varias cosas al mismo tiempo (multi-cabezas). Y al mismo tiempo tienen un mapa de “quién está en qué asiento” (positional encoding) para no perder el orden.
Así la “conversación” se entiende entera de un vistazo, sin depender de ir uno a uno.
¿Qué implicaciones tiene para embeddings y tu trabajo de embeddings?
Ya que en posts anteriores hablamos de embeddings, conviene destacar que los Transformers los usan de forma muy poderosa.
- Las arquitecturas basadas en Transformer generan embeddings contextuales: el embedding de una palabra depende de las demás palabras de la frase. Esto se diferencia de los embeddings estáticos (“manzana” siempre tiene el mismo vector) y es una evolución enorme.
- Gracias a la atención, esos embeddings contextuales pueden capturar relaciones complejas: qué palabras se relacionan entre sí, qué significado lleva una palabra en ese contexto, etc.
Por tanto, al entender el paper “Attention Is All You Need”, entendemos mejor por qué ahora usamos modelos que generan embeddings tan ricos y variados, y por qué ya no solo trabajamos con Word2Vec o FastText como antes.
Conclusión
El paper Attention Is All You Need representa un hito en IA. Introdujo una arquitectura que cambió la forma de construir modelos de lenguaje, de generar texto, de entender relaciones entre palabras, de manejar secuencias con gran eficacia.
Para ti, que ya trabajas con embeddings y análisis de texto, conocer este paper te da una base sólida para entender por qué las tecnologías actuales funcionan como funcionan, y cómo podrías plantearte usarlas o explicarlas en tu proyecto.
En próximas entradas podríamos ver cómo se deriva este paper hacia modelos específicos (como GPT, BERT…), cómo funciona el embedding contextual, y cómo tú mismo puedes aprovecharlo para análisis de comentarios, clustering, etc.