
Cómo construimos un pipeline de Social Listening 100% automático

Hace unos meses, a raíz de la asignatura “Proyectos III” de mi grado en Ciencia de Datos, nos vimos envueltos en un proyecto en colaboración con PricewaterhouseCoopers, en el cual, nos pedían hacer un trabajo con la temática “Social Listening”, sin dar ninguna indicación extra. Por tanto, estuvimos los últimos 5 meses reuniéndonos con ellos y fijando un objetivo común: diseñar una arquitectura de social listening que, solo con indicar el nombre de la empresa, recopilara los datos, los procesara y nos entregara insights de marca listos para presentar.
Y así es como nació este proyecto que desarrollé junto a mis inseparables Adrián Castillo, Carlos Serrano.
En este post te contamos cómo lo hicimos, qué descubrimos analizando a Apple y qué aprendizajes nos llevamos para futuros proyectos de análisis de redes sociales.
El reto: escuchar sin supervisión
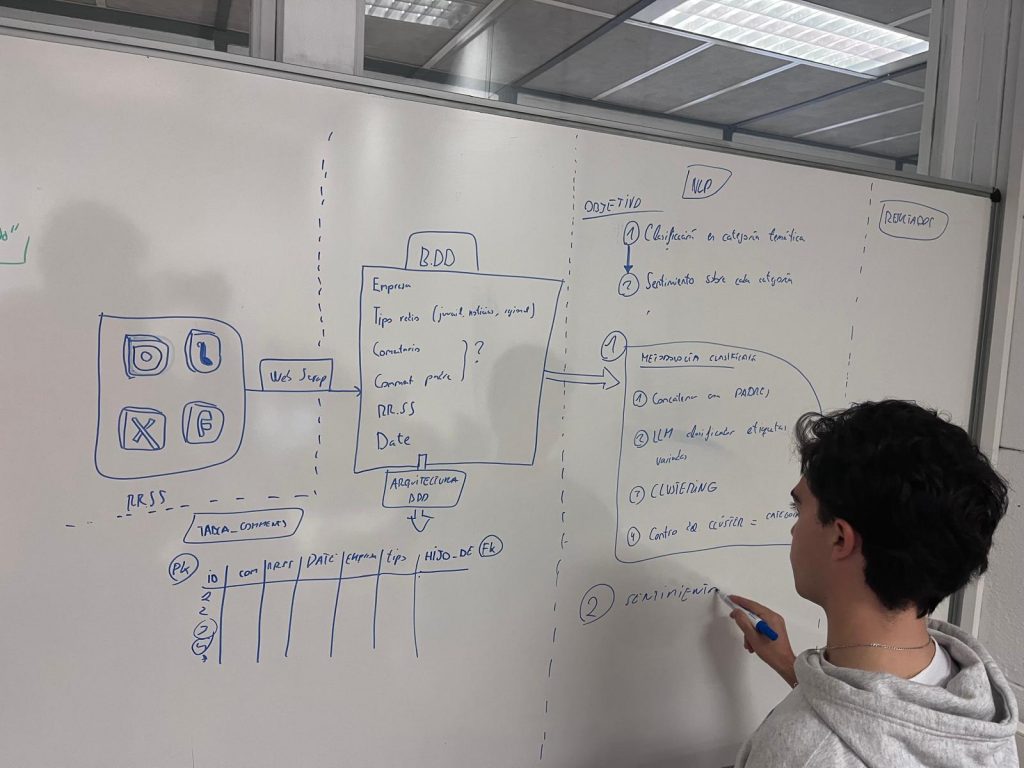
Nuestro objetivo era claro: automatizar de extremo a extremo el proceso de escucha social y reducir las horas invertidas en configuración y limpieza manual. Para conseguirlo, definimos cuatro hitos:
- Captura sin API
Desarrollamos un módulo de web scraping con Playwright que simula el comportamiento de un usuario real y esquiva los bloqueos habituales (rotación de User-Agent, tiempos aleatorios, etc.). Así extraemos comentarios públicos de cualquier red sin credenciales especiales. - Etiquetado temático dinámico
En lugar de clasificar con listas fijas, usamos un LLM local (Llama 3 8B) que asigna a cada comentario una etiqueta de 1-3 palabras. Después agrupamos esas etiquetas con HDBSCAN y embeddings para descubrir los temas latentes que preocupan a la audiencia. - Sentiment y puntuación de reputación online
A cada comentario aplicamos un modelo transformer multilingüe que decide si el tono es positivo, negativo o neutro. Con esa señal calculamos un Social Score por tema (–1 a +1) que nos permite comparar rápidamente. - Visualización instantánea
React + Tailwind generan un dashboard que se autocompleta cuando termina el pipeline: métricas globales, evolución temporal y un mapa 3D de temas para navegar la conversación.
En total, el flujo tarda unos 10 min en descargar 1 000 comentarios y una hora en etiquetarlos con IA en una CPU estándar; todo escalable si pasamos a GPU o paralelizamos procesos.
Datos y periodo analizado
Para la prueba de concepto nos centramos en TikTok (por su volumen y lenguaje coloquial) y rastreamos menciones a “Apple” entre julio 2022 y mayo 2025. El resultado fueron 45 000 comentarios listos para estudio.

Hallazgos clave: Apple bajo la lupa
Compartimos los insights más llamativos, útiles para cualquier marketer junior-mid que quiera aplicar social listening de forma práctica:
- Distribución de sentimiento
- 31 % positivo, 42 % neutro y 26 % negativo. Aunque la marca genera entusiasmo, existe una bolsa crítica que no debemos ignorar.
- Top 5 temas por volumen
- Batería del iPhone (Social Score –0,22)
- Ecosistema Apple (+0,35)
- Precios (–0,48)
- Privacidad (+0,41)
- Diseño (+0,44)
- Insight de marca revelador: los usuarios aplauden la integración entre dispositivos, pero perciben los precios como el principal freno a la compra. El equipo de producto podría explotar la ventaja competitiva del ecosistema mientras refuerza mensajes de valor para justificar el coste.
- Tendencia temporal
Durante los lanzamientos de septiembre, el sentimiento mejora hasta +0,12; tres meses después vuelve a la media. Las campañas de novedad funcionan, pero el efecto se diluye rápido.
Lo que aprendimos en el proceso
- El prompt engineering vale oro
Pequeños cambios en el prompt del LLM suponían pasar de etiquetas generalistas (“calidad”) a menciones muy concretas (“chip M3”). Invertir tiempo aquí elevó la precisión del clustering. - La modularidad facilita la iteración
Separar el scraping, el NLP y la capa de visualización nos permitió afinar cada pieza sin romper el resto. El próximo paso será conectar bases de datos gráficas para optimizar la búsqueda de hilos. - Velocidad vs. profundidad
Una hora de CPU por 1 000 comentarios es aceptable para prototipos, pero en producción necesitaremos GPU o segmentar por lotes. La buena noticia es que el ahorro de configuración compensa con creces ese coste. - Reputación online ≠ volumen de menciones
A veces un tema minoritario (p. ej., “privacidad”) pesa más en la percepción global que el hype alrededor de un nuevo dispositivo. Mirar solo las curvas de volumen puede llevar a conclusiones erróneas.
Conclusión y próximos pasos
Construir este pipeline nos ha enseñado que el verdadero valor del social listening no es acumular datos, sino entregar insights de marca accionables en horas, no en semanas. Si estás empezando en marketing analítico, nuestro consejo es automatizar pronto las tareas repetitivas para dedicar tu tiempo a interpretar resultados y proponer acciones que mejoren la reputación online.
Tal fue la acogida del proyecto que incluso desde PwC nos invitaron a sus oficinas de Madrid para presentarlo en persona. Pero esa es otra historia… que quizá comparta en el próximo post.
¿Quieres ver el proyecto completo?
Aquí te dejo los documentos que preparamos: