
La magia de los embeddings: cómo podemos relacionar semánticamente palabras a través del mundo numérico

Vivimos rodeados de contenido escrito: palabras, párrafos, conversaciones. Pero… ¿cómo hace una máquina para «entender» que “rey” y “reina” están relacionados, o que “chico”-“chica” tienen una relación de género y semejanza? La respuesta pasa por un concepto mágico (o al menos muy ingenioso) llamado embeddings.
En este artículo vamos a explicarlo de forma asequible, sin necesidad de que seas un experto en IA o procesamiento de lenguaje natural.
¿Qué es un embedding?
Un embedding es, dicho de forma sencilla, una representación numérica de una palabra (o frase, o incluso imagen) en un espacio de números (vectores) de forma que la cercanía en ese espacio refleje cercanía en significado. (IBM)
Imagina que cada palabra es llevada a un cohete que la deposita en un universo de números, y que las palabras que “significan cosas parecidas” aterrizan relativamente cerca unas de otras.
¿Por qué “convertir palabras en números”?
Porque los algoritmos de máquina trabajan con números. Las máquinas no “ven” directamente los significados como lo hacemos nosotros; ven vectores, matrices, operaciones. Si podemos representar palabras por vectores numéricos que codifican su significado o uso, entonces podemos usar operaciones matemáticas para encontrar similitudes, relaciones, analogías… (milvus.io)
En resumen: palabras → vectores → operaciones matemáticas → descubrimos relaciones.
¿Cómo funcionan, de forma ligera?
Aquí va un esquema sin profundizar en fórmulas:
- Se toma un gran corpus de texto (muchos libros, artículos, webs)
- El modelo observa contextos: qué palabras aparecen cerca de otras, en qué oraciones, etc.
- A partir de eso, aprende a asignar a cada palabra un vector (por ejemplo, 100-dimensiones, 300-dimensiones…) de números reales. (GeeksforGeeks)
- Esos vectores están organizados de tal forma que palabras usadas en contextos similares acaban “cerca” unas de otras en ese espacio vectorial.
- Y lo más sorprendente: también se pueden hacer operaciones como “rey” – “hombre” + “mujer” ≈ “reina”. Esto demuestra que la geometría del espacio numérico captura relaciones semánticas. (milvus.io)
Ejemplo: chico-chica y rey-reina
Para ponerlo en un ejemplo claro:
- Supón que el vector de chico es → v_chico.
- El vector de chica es → v_chica.
- Supón que el vector de rey es → v_rey.
- El vector de reina es → v_reina.
Entonces, en muchos modelos de embeddings sucede algo como:
v_chico → v_chica ≈ la misma “distancia” o “cambio” que v_rey → v_reina
Es decir: “chico a chica” es simbólicamente parecido a “rey a reina”.
Si haces:
v_rey - v_chico + v_chica ≈ v_reina
obtienes que el vector resultante se encuentra muy cerca de v_reina. Esto demuestra que el modelo ha capturado que “hombre → mujer” es equivalente a “rey → reina”.
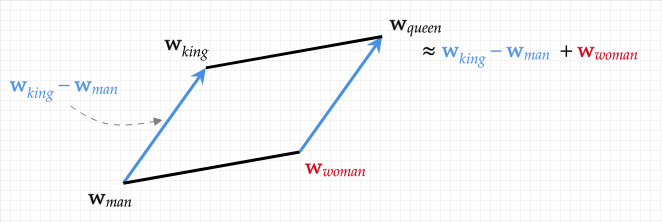
Este tipo de analogías matemáticas son una de las “magias” de los embeddings. (milvus.io)
¿Por qué es tan útil?
Porque gracias a los embeddings podemos:
- Medir similitud entre palabras: ver qué tan cerca están dos vectores para saber qué tan relacionados están los conceptos.
- Clustering y agrupación de palabras o documentos por significado.
- Encontrar analogías, como en el ejemplo anterior.
- Usarlo en tareas de búsqueda, recomendación, procesamiento de lenguaje, traducción automática… Embeddings son la base de muchos sistemas modernos de IA lingüística. (turing.com)
Metáfora para entenderlo
Piensa en un mapa de ciudades. Cada ciudad es una palabra. En un mapa normal, las ciudades que están geográficamente próximas tienen cosas en común (clima, cultura, etc.). En el “mapa de significado” de los embeddings, las “ciudades‐palabras” que están próximas tienen significados o usos similares.
Y lo mejor: podemos hacer “viajes” en ese mapa (sumas y restas de vectores) para pasar de un concepto a otro.
Cuestiones adicionales a tener en cuenta
- No todos los embeddings son iguales: los hay “estáticos” (cada palabra siempre tiene el mismo vector) y “contextuales” (el vector depende del contexto en que aparece la palabra). (Wikipedia)
- Los embeddings pueden capturar sesgos del texto de entrenamiento (por ejemplo de género, raza, etc). Es importante tenerlo presente. (Wikipedia)
- Aunque la representación numérica es potente, no reemplaza la lectura humana, los matices, el contexto cultural… Es una herramienta.
¿Qué puedes llevarte?
Si algo te llevas de este artículo, que sea lo siguiente:
- Un embedding es una representación en números de un concepto lingüístico (palabra, frase) de forma que cercanía = semejanza.
- Esta representación permite operaciones matemáticas que descubren relaciones entre palabras (como chico-chica, rey-reina).
- Gracias a esto, los sistemas de lenguaje pueden “entender” mejor el significado, no solo las palabras en bruto.
- Es una tecnología central en el mundo de la IA y del procesamiento de lenguaje natural, con muchas aplicaciones prácticas.
Conclusión
La magia de los embeddings reside en traducir el significado a números y luego jugar con esos números para descubrir relaciones que, de forma implícita, ya existen en el lenguaje. Desde la analogía “chico → chica” hasta “rey → reina”, estamos ante estructuras que un día parecían exclusivamente humanas y que ahora podemos capturar con vectores.
En el blog seguiremos explorando cómo estos conceptos aparentemente técnicos se abren camino en proyectos reales, y cómo tú también puedes aprovecharlos — aunque no seas experto en IA.